
はじめに
こんにちは。新規事業のプロダクトマネジメントを担当している taison です。
先日、顧客への請求金額を算出するために日々実行しているデータフローを刷新しました。 その際に Datastream という Google Cloud が提供する CDC サービスを活用したことで、構築・運用が楽になったのでご紹介します。
なお今回は開発にご協力いただいている 株式会社 Rabee の abyssparanoia さんの提案・検証があって実現したので、ここで感謝させていただきます。
全体像
それまではとある BI ツールを活用して、請求根拠となるデータを各内容にあわせて出力するデータフローを組んでいました。 下図のように、プロダクトの RDB(アプリケーションデータ)そのものに直接接続し、BI ツールで生成したクエリを定期的に実行することで要件を満たしていました。
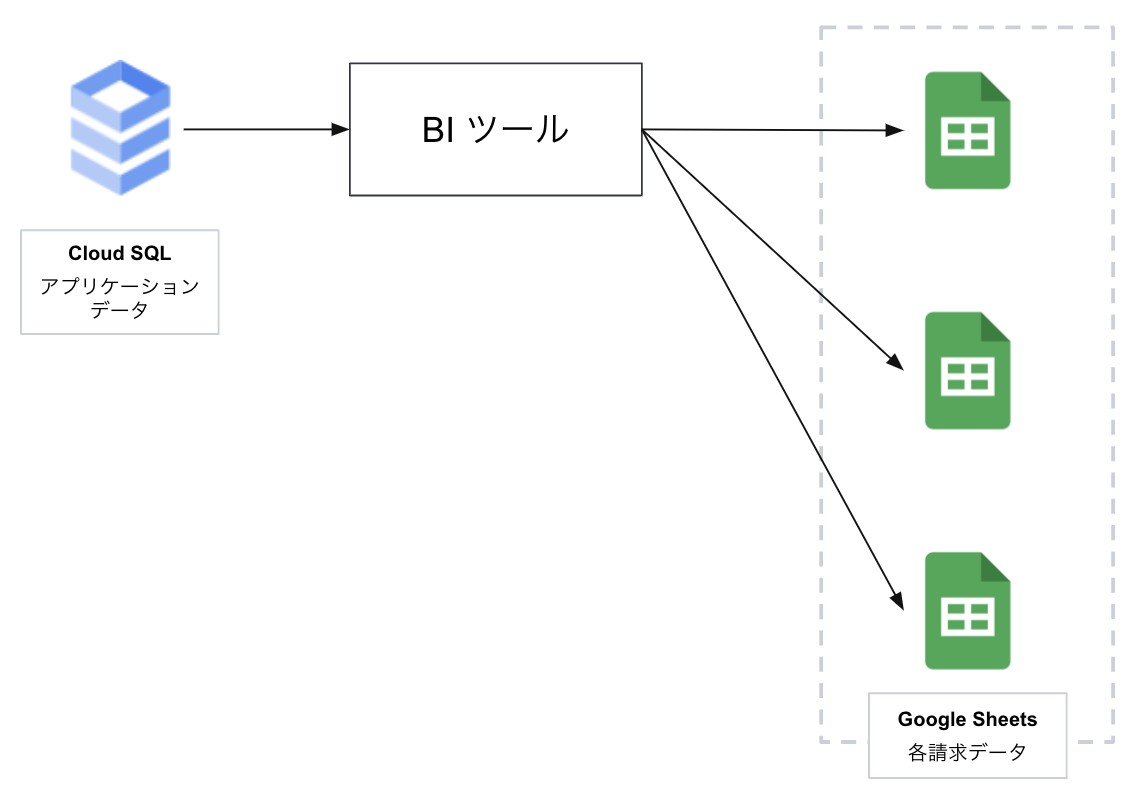
ただ、おかげ様で事業が成長するとともに、対象となるデータのレコード数が増えたことで、BI ツールの提供するバッチ機能で取り扱えるレコード数の上限を超えたため、対応できなくなってきました。 また定期で実行されるクエリもプロダクトで利用している RDB に少なからず負荷を与えていたこともあり、移行を検討しました。 (クエリについてはもっと最適化できたでしょうが、初期フェーズということもありツール上で操作が完結することを優先しました)
そこで今回は以下の点を念頭に、データフローを検討しました。
- あくまで請求等の確認に用いるものなので、リアルタイムの同期は不要
- 過去の請求データ(およびその根拠となるデータ)は保持しておきたい
- 要件(クエリ)は変更する可能性がある
自前でバッチを組むことも選択肢にありましたが、下図のように Google Cloud が提供するサービスを組み合わせることでデータフローを移行できました。
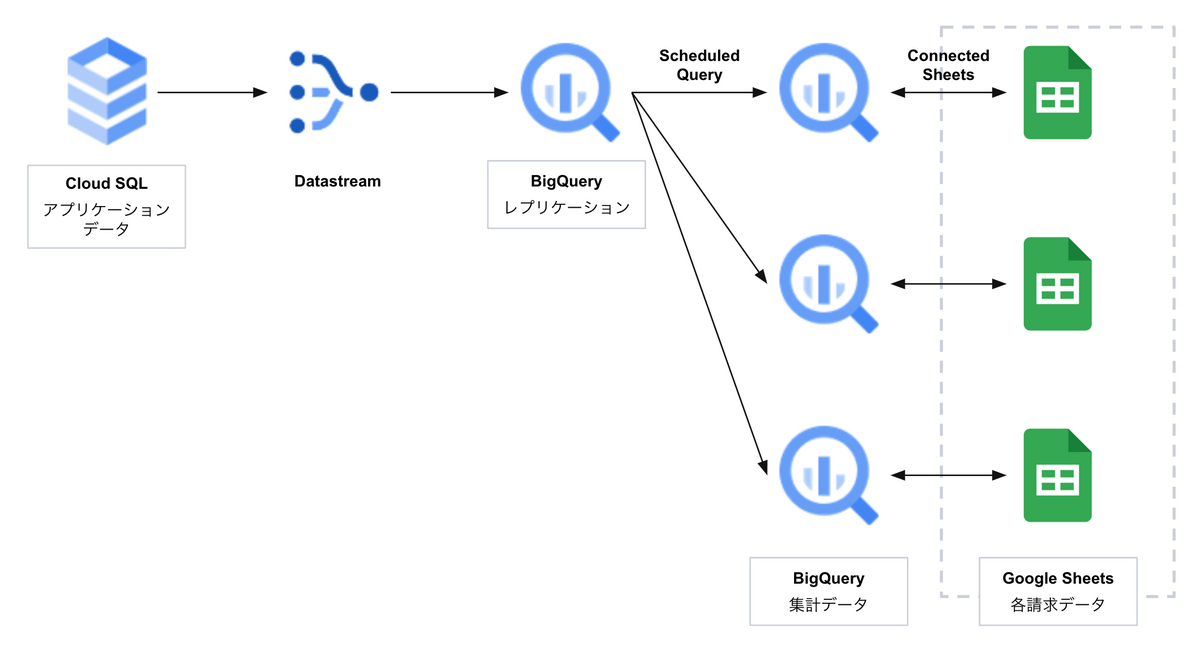
- Datastream(CDC サービス)で定期的にアプリケーションデータのレプリケーションを BigQuery 上に構築
- レプリケーションから Scheduled Query で各請求の要件に合わせて集計データを出力
- 実際に請求処理を行うメンバーが扱いやすいように Connected Sheet でスプレッドシート上に連携
サービスを活用することで、比較的構築と運用を楽にできました。 また後述しますが、今回のケースではコストを安くすませることができました。
まさに 「うまい、やすい、はやい」 を実現できたと感じています。
やったこと
Google Cloud の Datastream を使ったデータ同期
今回活用した Datastream について、基本的には公式ドキュメントを参照ください。 その上でいくつかポイントを説明します。
CDC について
CDC(Change Data Capture)はその名の通り、トランザクションログから「変更されたデータの差分を取得する」仕組みです。そのため RDB にクエリ等の負荷をかけずにレプリケーションを作成できます。
Datastream について
Datastream は CDC のサービスとして、Google Cloud の対応サービスへデータを同期できます。
- 同期元となる「ソース(Source)」と同期先となる「宛先(Destination)」の接続設定を行う
- 今回はソースとして Cloud SQL を、宛先として BigQuery を設定しています
- その接続設定をつかってデータを転送する「ストリーム(Stream)」を設定する
基本的には以上です。 その上で、Datastream では以下の2つを設定できます。
- ソース:どのテーブルを同期するか
- 今回はアプリケーションデータから全てのデータを同期する必要はなかったので、請求に必要なデータのみに絞ってレプリケーションしています。それによって、転送するデータ量は減らせますし、センシティブなデータを対象外にすることで余計なリスクを排除できます
- 宛先:どれくらいの頻度で同期するか(どれくらい古いデータを許容するか)
- 今回はあくまで請求時と売上の確認に必要な程度だったので、リアルタイムに同期を取る必要はなく、1時間程度に設定しました。この頻度が増えればコストが上がり、減ればコストが下がることにつながります
ここは要件とコストのバランスを見ながら調整するのがよいでしょう。 また現状では Merge と Append-Only(最近追加された)のみで、キャプチャするイベントについての細かい設定ができない(INSERT と UPDATE のみを CDC で反映させ、DELETE キャプチャを無効にする、など)ので今後に期待しております。
これで RDB のアプリケーションデータから BigQuery 上にレプリケーションを構築できました。
Scheduled Query + Connected Sheets で安全に BQ のデータを扱う
今回活用した Scheduled Query と Connected Sheets について、基本的には公式ドキュメントを参照ください。 その上でいくつかポイントを説明します。
Scheduled Query について
Scheduled Query は、BigQuery に対してスケジュールを組んでクエリを定期実行し、データを転送させるバッチをフルマネージドで作成・運用できるサービスになります。
基本的には実行したいクエリと転送先、そしてスケジュールを指定すれば完了です。 1点だけ、転送バッチで BigQuery Data Transfer Service を活用しているとのことで、定期実行するための権限を設定する必要があります。そのため、あらかじめ IAM を作成しておく必要があります。(個人も紐付け可能ですが、管理面を考慮し専用の Service Account を作るのがよいでしょう)
今回は BigQuery 上のレプリケーションに対して、目的に合わせて異なるクエリを定期実行し、それぞれテーブルとして書き出すようにしました。Overwrite で洗い替えすることで、最新の情報が取得できるようにしています。また実行頻度も目的に合わせて1時間〜1日で設定を変えています。
ここも基本的にはクエリの実行にのみ課金されますのでコストとのバランスで頻度を調整するのがよいでしょう。
Connected Sheets について
Connected Sheets は BigQuery にアクセスし、スプレッドシート上で様々な操作ができるようになります。
詳しくは割愛しますが、BigQuery の権限を持っていれば、メニューから Data Connector で上記にて作成したテーブルに接続できます。すると、すぐにプレビューを見ることができ、各操作もできるようになります。 (ただ Workspace のプランによっては、そもそも Connected Sheets が使えないため、詳細はご確認ください)
実は Connected Sheets から直接 BigQuery にカスタムクエリを発行可能です。そのため、わざわざ各集計テーブルを作成する必要はありません。 ただ、今回の要件ではスプレッドシートを使うメンバーはあまり BigQuery に習熟しておらず、操作上の不安がありました。特にありがちなうっかり BigQuery に対して操作範囲が広かったり、負荷の高いクエリかけてしまうリスクがあるため、お互いの安全性を考え、今回の方法を選択しました。
結果
実際に移行することで得られた効果は以下になります。
- Google Cloud が提供するサービスのみを利用することで、構築・運用が手軽
- 弊社では terraform を利用しているため構築はコードベースで推進しましたが、ブラウザからの画面の操作で構築・運用が完結します
- Datastream はサーバレスで、現状でスケーラビリティを意識する必要がない
- 今後データ量が増えた場合においてもあまり意識する必要がない構成というのは、リソースが限られる新規事業を推進していく上では大きなメリットになります
- コストが安い
- 現状、アプリケーションデータ自体は 1000 万レコードに満たず、ストリーミングやスケジュールクエリの実行頻度は前述の通りになります
- そのためコストはほぼ Datastream のみになりますが、以下のように今月は 0.2 ドル以下を想定しています(7/1 ~ 7/23 執筆時点)

最後に
CDC 使ってみたら、今回のケースはハマりました。なんとなく高コストなイメージをもっていたので、そこが抑えられたことで身近になりました。今後はデータ分析での活用や、プロダクトでイベントを扱うところでもチャレンジしたいです。
▼ エンジニアの採用やっています! 興味あれば是非お声がけください https://herp.careers/v1/repro/requisition-groups/07e6d8e3-4222-45f0-8b02-4cabf43aed4a