
はじめに
Reproで開発を担当しているEdward Fox (edwardkenfox) です。2021年頃から Repro Booster というプロダクトの立ち上げに携わっており、開発を通して得た知見を共有できればと思い立ち筆を取るに至りました。4年ぶりのテックブログ執筆で少しばかり緊張していますが(?)、張り切ってやっていこうと思います。
Repro Boosterとは
2022年11月に正式リリースした、ウェブサイトの表示速度向上を実現するサービスです。「タグを入れたその日から、Webサイトが速くなる」というタグラインのもと、タグ(JavaScript)の設置だけでウェブサイトの表示速度が簡単に実現できるということで、リリース以来多くのお客様・サイトでご利用いただいています。
Repro BoosterではServiceWorkerと呼ばれる技術を最大限活用して多くの機能が実現されているのですが、このServiceWorkerというものはとても便利でパワフルな反面、従来のWebフロントエンドの開発とはひと味もふた味も違います。
ServiceWorkerとは
ServiceWorkerについての詳細な説明はMDNの記事などに譲ります。大事なのは、これまでのJavaScriptを利用したWebフロントエンドの開発とはパラダイムが大きく異なる、という点です。具体的には
といった点が挙げられます。こういった特徴を備えていることでWebプッシュ通知といった機能/仕様が実現でき、また他にもメジャーな応用としてオフライン対応なども存在します。これ以外にも多くのユースケースが考えられますが、Repro Boosterの開発を通してServiceWorkerと向き合ってきた印象としては、ServiceWorkerならではのクセや仕様を熟知していないと実装が難しい場面をいくつも経験しました。これらを「落とし穴」として紹介し、これからServiceWorkerを利用した開発を行う人にとって少しでも有益な情報を提供できればと思います。
ServiceWorkerの落とし穴8選
1. ライフサイクルの難しさ
ServiceWorkerは通常のJavaScriptのようにHTMLにインラインで書き込んだり、 <script> で読み込んで実行させることはできません。ページから navigator.serviceWorker.register(URL) というAPIを通して、サイトと同一オリジンに配置されたServiceWorkerファイルを指定して起動させる必要があります。ServiceWorkerはページからは独立したプロセス/スレッドライフサイクルとして起動され、ページとは異なるライフサイクルによって制御されます。ServiceWorkerのコードは基本的にすべて fetch や activate といったイベントに対するリスナーとして記述しますが、特にServiceWorkerの更新時に関わってくるイベントや状態遷移がとっつきにくい印象があります。
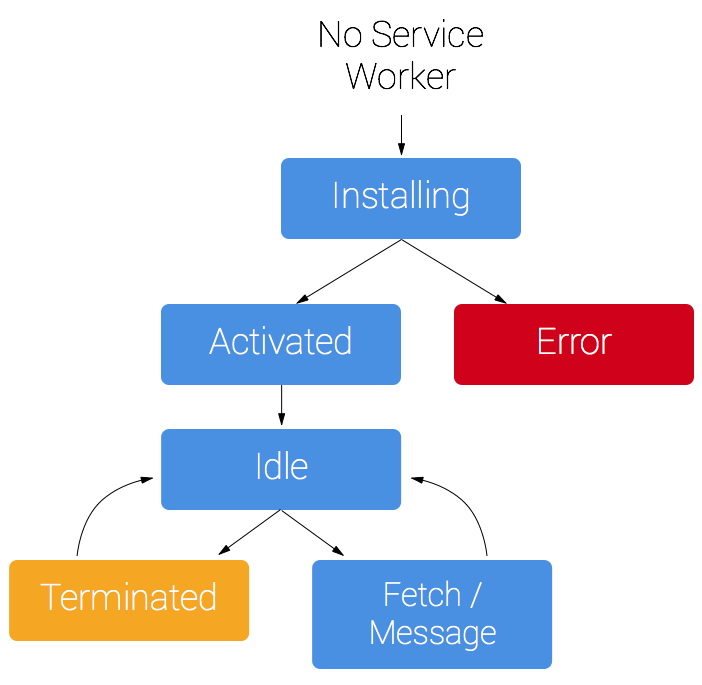
また web.dev – The service worker lifecycle にも
The lifecycle of the service worker is its most complicated part.
とあるくらいなので、ServiceWorkerの利用をする際にはこれらドキュメントをよく読んで理解しておくと良いでしょう。
2. スコープとページコントロールという概念
ServiceWorkerを扱う上では、スコープという概念・仕様についてもよく理解しておく必要があります。Webプッシュ通知を実装したりする分にはあまり気にする必要がないのですが、 fetch イベントのハンドラを利用するに場合は、ServiceWorkerファイルの設置場所とスコープの指定によっては意図通りに動作しないこともありえるでしょう。
ServiceWorkerのスコープは navigator.serviceWorker.register() というAPIを呼び出す際に { scope: "/" } というオプションを通して指定します。ServiceWorkerファイルのURLと指定されたスコープが食い違う(= ファイルが設置されているよりも上位のスコープを指定する)場合は、そもそもServiceWorkerが起動しません。また複数のServiceWorkerが異なるスコープで登録されているときに、どのServiceWorkerがページのコントローラとなるか(= fetch イベントを受け取るか)についての詳細な仕様もあるため、このあたりの概要も理解しておくと実装がスムーズに進められるでしょう。ServiceWorkerのスコープについては、nhirokiさんの次の記事がとても参考になります。
3. キャッシュレイヤーとの前後関係
ServiceWorkerは多くの場合で Cache Storage というストレージ領域と併用されます。ServiceWorkerはページから独立しており、かつほぼ全てのAPIが非同期になっているため、CookieやlocalStorageといった従来頻繁に利用されていた保存領域にはアクセスできません。IndexedDBの利用も可能ですが、ネットワークのプロキシとして振る舞うことも考えると、Response オブジェクトをそのまま格納できる Cache Storage を使うのが妥当なケースが多いでしょう。
ここでよく理解しておきたいのがHTTPキャッシュとServiceWorkerおよびCache Storageの位置関係です。ページ(= DOMやJSのランタイム), HTTP Cache(diskからヒット), HTTP Cache(メモリからヒット), ServiceWorker(Cache Storage), ネットワークの位置関係を整理すると、Chromiumの実装では下図のようになります。
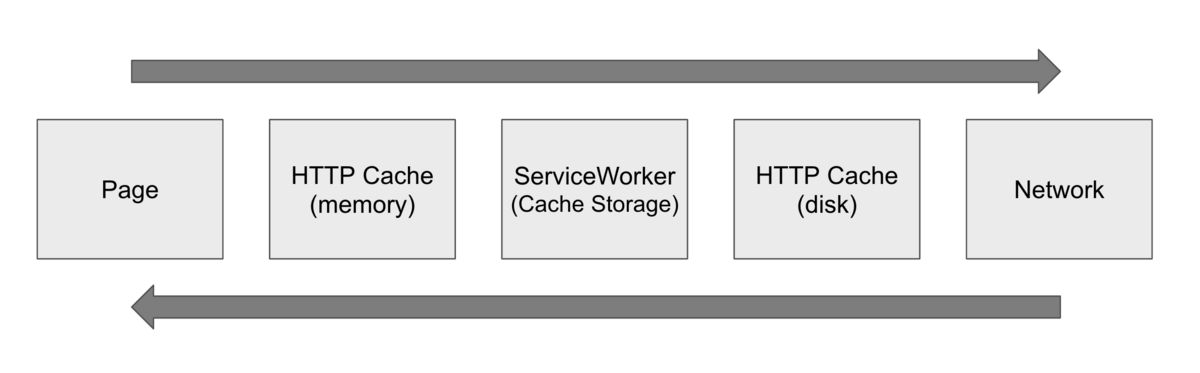
cache-control ヘッダを付与したレスポンスを受け取り、リソースがHTTP Cacheとして再利用される場合の挙動に注意する必要があります。具体的には、memory cache がヒットし再利用される場合はリクエストはServiceWorkerまで届かずに完了します。一方でdisk cacheからヒットした場合、ServiceWorkerを経由してネットワークから取得し直す代わりにdisk cacheから返ってくることになり、ServiceWorkerから見ればネットワークから取得したのと同じ扱いになります。 cache-control を通してHTTPキャッシュに関する指示を出すことはできても、HTTPキャッシュがdiskから再利用されるか、あるいはメモリに載るかは決定的ではありません。
また、ServiceWorkerがCache Storageにリソースを格納して再利用する場合には、HTTP cacheと違って cache-control の記載内容に従って自動的にキャッシュが有効期限を向かえて再取得されるといった挙動はなく、そういった有効期限の管理は自分で実装する必要があります。このため、キャッシュ戦略とリソースごとのキャッシュ可否についてよく検討した上で利用する必要があると言えるでしょう。ServiceWorkerを利用する際のキャッシュ戦略については web.dev – Service worker caching and HTTP caching に詳しく書かれているため、こちらを参照してください。
なお、上記はChromiumでの実装について言及しており、またブラウザ内キャッシュについての完全な説明ではありません。ブラウザによっても実装が異なる可能性があるため、その点も併せて認識しておくと良いでしょう。
4. ブラウザ間の挙動の違い
ServiceWorkerはChromeが2015年に先駆けてリリースし、続けて2016年にFirefoxで、その後2018年にSafariでリリースされました。リリース後も積極的に追加の機能や仕様変更が入り、利便性・パフォーマンスともに向上していっていますが、非常に込み入ったバグや仕様上で未解決な点なども残っています。こういった背景から考えても、ブラウザごとに細かい部分で挙動の差があっても不思議ではありませんし、使い込むほどそういった点に悩まされることがあるのも事実です。
たとえばSafariでは、body付きのリクエストをハンドルする際に、1度でもbodyにアクセスするとそのリクエストが壊れるバグがありました。下記のWebKitのチケットでは、デバッグのために console.log(request.body) するとエラーが出る、という事象が報告されています。このチケット自体はすでにcloseされていますが、以前に私が確認したタイミングではまだ同じ問題が継続して発生するように見えていました。
また ServiceWorkerRegistration.update() というAPIを呼んでServiceWorkerの更新を行う際にも、そのタイミングで発火するServiceWorker URLへのHTTPリクエストの詳細も異なっていたりします。具体的には、このAPIをページ側のJavaScriptから呼ぶか、あるいはServiceWorkerファイルから呼ぶかでリクエストのヘッダに違いがあり、なおかつこの2つのケースにおいて Chrome と Safari の Referer ヘッダや Origin ヘッダを見ると一貫性が見られない、という内容です。
こういった点をすべて事前に理解して予防的に実装を行うことができれば理想的なのですが、なかなかそれは難しいのが実情です。多くのフロントエンド開発者はDevtoolsの便利なChromeを利用して実装とデバッグを行っているかと想像していますが、少なくとも実装後の動作確認はChromeとSafariのどちらも行うのが良いでしょう。また可能であれば、ブラウザを起動してプログラムの挙動をテストする end-to-end な自動テストを組み込むことなどを検討するのも、テスト効率化の観点から望ましいです。
5. デバッグのしづらさ
ServiceWorkerは通常のページと異なるライフサイクルを持っていることに由来して、デバッグのやり方も通常のJavaScriptとはやや異なり、いくつか気をつけるポイントが存在します。例えばChromeのDevtoolsでは「Update on reload」という設定にチェックをしないと、手元で更新したServiceWorkerが反映されずに混乱することがあります。ServiceWorkerを利用した開発時のデバッグについては次の記事にまとまっているので、こちらを参照してみてください。 Chrome Developers – Troubleshooting and logging
他にも、SafariのServiceWorker用のDevtoolsパネルは挙動が不安定な様子が見受けられ、ブレイクポイントやconsole.logなどを組み合わせてデバッグしようと思っても思い通りにならないこともありました。根本的な解決策はありませんが、こういった点も事前に把握して開発に入れると安心です。
6. CMSなどの制約によってServiceWorkerをルートに設置できないことがある
この点はServiceWorkerそのものについてではなく、ServiceWorkerを利用する環境に関する話のためここまでの内容と毛色が違いますが、意外と見落としがちな点のため記載しています。
ServiceWorkerを利用するにあたっては、サイトと同オリジンでServiceWorkerファイルがHTTPSでアクセス可能になっている必要があります。大抵のケースではServiceWorkerを静的ファイルとしてWebサーバーに置くことが多いと思いますが、HTTPSでアクセスして適切なコンテンツが返ってきさえすれば問題ないので、アプリケーションサーバーで動的にレスポンスを返す形で導入することも可能です。
ただし、上記に記載したケースはいずれもサーバーの設定や実装に手を入れることができる前提であり、そうでない環境下でWebサイトやサービスを運用している場合はServiceWorkerファイルを設置できないケースがあります。具体的には、CMSサービスやサイトの用途に応じたパッケージ/ツールを利用している場合などです。こういった環境においては、任意のファイルを設置できるのが特定のパスに限定されていることが多く(典型的には /assets/js/ など)、サイトのルートにServiceWorkerを配置し { scope: "/" } として起動することができません。Service-Worker-Allowed というレスポンスヘッダを使えば、ServiceWorkerファイルの設置されたパスとは異なるスコープでServiceWorkerを起動することが可能になりますが、CMSではヘッダの追加や編集にも制約がかけられていることが多いため、そういった場合には導入自体が難しくなってしまいます。
7. 実装をミスるとサイトが壊れる
ServiceWorkerはページとネットワークの間に立つプロキシとして振る舞いますが、セキュリティ上の制約事項が多い反面で与えられている自由も多いため、リクエストやレスポンスを自由に書き換えることができます。Cookieの読み書きなど制約が残る部分も多くありますが、初めてServiceWorkerを触る人は与えられている裁量の大きさに驚くこともあるでしょう。しかしながら、大いなる力には大いなる責任が伴います。ServiceWorkerコードに不備があると、最悪のケースではページが一切表示されず、ブラウザのエラー画面が出続けてしまったり、特定のリクエストが永遠に完了しない、といった結果になってしまいます。たとえば fetch ハンドラの中で Request オブジェクトを壊してしまうと、次の画像のようになることがあります。

そもそもこういったバグや不具合は起こさないことが望ましいですが、それでも起きてしまったときの回避策は用意しておくに越したことはありません。おそらくもっとも確実な方法は Clear-Site-Data というHTTPヘッダを通してServiceWorkerRegistrationを根こそぎ消してしまうことなのですが、本記事の執筆時点においてはSafariで未サポートであり、またそもそもページへのリクエスト自体が壊れている状況下ではこのヘッダを受け取ることができないため、利用できるケースは限られるでしょう。また「6. CMSなどの制約によってServiceWorkerをルートに設置できないことがある」にも記載のように、HTTPヘッダを追加/編集できない環境下ではそもそも利用が難しいという問題もあります。
バグのあるServiceWorkerを止める方法としては、問題のあるServiceWorkerファイルを「kill-switch」と呼ばれる内容で更新してしまう方法があります。kill-switch ServiceWorkerについては、次の記事を参照してください。
- stack overflow – How can I remove a buggy service worker, or implement a "kill switch"?
- Chromium Docs – Service Worker Security FAQ
また kill-switch ServiceWorker の用意に加えて、ServiceWorkerの登録時に指定できる updateViaCache: "none" というオプションの利用も併せて検討すると良いでしょう。ServiceWorkerには「24時間以内にServiceWorkerファイルの中身に変更がないかチェックし更新を適用する」という仕様がありますが、多くのケースではこれよりも早く変更を適用したいと考えられ、そういったケースにおいては updateViaCache: "none" の指定が有効でしょう。
Chrome Developers – Fresher service workers, by default
8. ServiceWorker自体にオーバーヘッドがある
ここまでは主に機能や仕様、実装面について言及してきましたが、当然パフォーマンスにも注意する必要があります。考えてみれば至極当たり前のことではあるのですが、ServiceWorkerというのはそれ自体が通信における追加のレイヤーとなるため、ServiceWorkerを通ること自体のオーバーヘッドが存在します。これに加えて fetch ハンドラの中で複雑な処理を行えばその実行時間も加算されるため、非常にシビアにパフォーマンスを計測しながら実装を進めないと、「オフライン対応はできたけど遅くなった」というような顛末になりかねません。jakearchibald.github.io – SW Benchmark を見てみると、ServiceWorker自体が持つオーバーヘッドがどの程度なのか視覚的に分かると思います。
なお ServiceWorker自体のパフォーマンス向上として、Chromium では No-op ServiceWorkerの最適化なども実施されています。今後も性能向上とともにユースケースが拡大されるのを期待したいですね。
Chrome Platform Status – Feature: Skip service worker no-op fetch handler
おわりに
「ServiceWorkerの落とし穴」として8つのポイントを紹介させてもらいました。ハマりどころの多いServiceWorkerですが、しっかりと作り込めばとても便利で、これまでのWeb開発では考えもしなかったユースケースが実現できます。Repro Boosterの開発を通して、可能性に満ち溢れたServiceWorkerをうまく使いこなし、より使いやすく便利なWebの体験を提供するべく邁進しています。
ということで、Reproでは大量のデータを活用したマーケティングオートメーションだけでなく、Repro Boosterといった新製品の開発にも積極的に取り組んでいます。事業としても技術的な観点からもチャレンジングな環境なので、ぜひ興味を持たれた方はWantedlyからお気軽にご応募ください!